
Welcome to the second post in my series, “DevOps in a Regulated and Embedded Environment”. In this part, we’ll take a look at how a normal git workflow needs to adapt in a regulatory environment, and how tooling can support the necessary changes. Namely, regulation may stop the development team from releasing a planned feature, so any development process must allow for separate, long-lived versions of the software in various stages of releasability. We can fix this problem with proper use of git branches, but the problem isn’t trivial.
Git Flow?
Git is a tool of tremendous power. And like any other powerful tool, rules-of-thumb and workflows help to guide day-to-day usage and minimize the chance of self-inflicted wounds to the foot. There are many ways to go. The Linux kernel team appoints a dictator and a number of specialized lieutenants that manage their own technical fiefdoms and control what code makes it into the kernel. GitHub pushes a pull-request model where new code makes it into a codebase at the approval of the owner after review. The former works well for large and highly distributed teams whereas the latter works well for smaller distributed teams where a single owner can serve as the gatekeeper. Both models, with the GitHub approach being a scaled-up version of the one used by the Linux kernel, work well when trust is uncertain and contributors may come from anywhere. However, in most organizations, the software team is a localized unit consisting of vetted individuals whose incentives line up with the success of the organization (we hope!). In this case, a different workflow is needed, especially when most members of the team likely have direct access to push to the centralized, blessed, repository.
For these reasons, and for most teams, we at Coveros recommend the use of a git branching model known as ‘Git Flow’. In brief, Git Flow recommends git branches to split up work and isolate where changes occur to facilitate testing and rapid integration. The default master branch is kept as the single source of truth for production, defined as appropriate for the team. A development branch is introduced to serve as the mainline for on-going work that is in the process of being developed and tested. Team members are encouraged to fork feature branches from development for their day-to-day work and these branches are merged back to development on a daily (or more frequent) basis. Short-lived release and hotfix branches are used to get code into production. A more formal introduction to this workflow can be found here and a plugin to help enforce this workflow can be found on GitHub. Really, though, there’s no need for a separate tool, so long as the team buys into the workflow and resolves to adhere to it.
Git Flow in a Nutshell:
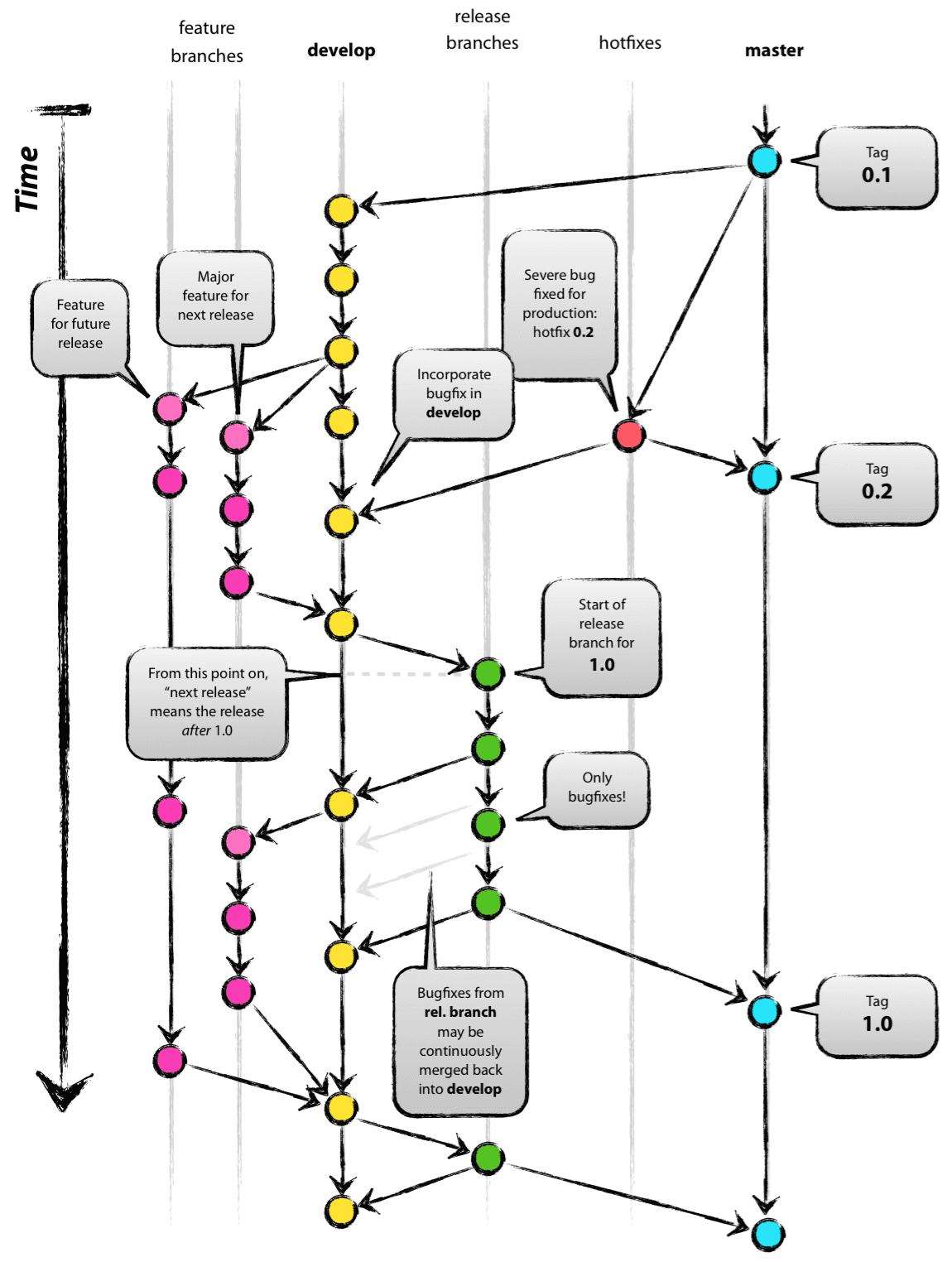
(Taken from http://nvie.com/posts/a-successful-git-branching-model/ on 10/20/2016)
Frequent integration is a crucial and critical part of this model. It enables a rapid feedback cycle that quickly alerts the team to potentially problematic parallel developments that will require manual intervention to resolve. Enforcing the frequency of integration ensures these manual merges are as small and painless as possible and gets to the core of why we recommend continuous integration and continuous deployment (CICD) practices for all organizations — releasing code should be a business decision and all technical hurdles should be dealt with when they are most easily resolved. After all, what good are developed features that can’t be delivered to a customer? They’re just investments the business has made that haven’t yet, and may never, pay off. Long-lived feature branches are, broadly speaking, a bad idea and usually indicate a broken development process for this and other reasons.
But I can’t merge back daily…
However, in my recent heavily-regulated project the Git Flow model was not workable — not because of a broken process but due to the constraints under which they must operate. The company manufactures medical devices and are therefore subject to FDA regulations on the software and firmware they develop for these devices. In particular, changing functionality or introducing a new feature requires approval from the regulatory body prior to release. Approval is never certain and requires testing and test data to demonstrate that the feature works as designed and that potential risks are identified and mitigated. This means that the feature has to be developed and tested in the lab before the code can be released to anybody, even for limited release testing. In particular, this makes the daily merge of feature branches back to development hazardous and potentially expensive when approval is not granted for a feature but a release needs to happen anyway. The safest way to deal with this reality is to keep in progress features out of the development branch until approval is actually granted. After all, merging two branches is easy. Unmerging who-knows how many feature branches to rip out one or more epics worth of functionality is error-prone, difficult, and potentially catastrophic.
One possible approach is to use the Git Flow model as-is and give up on frequent integrations. However, this means cutting a release is a painful endeavor where epics and stories that were developed in isolation have to be merged back together and all confidence is lost on the testing done up to that point. The merge itself is expensive, and with a device that requires significant manual testing, so is the required end-to-end testing. Fundamentally, there’s no reason to be confident that the integrated code line works in any way like the isolated branches.
Can we get this confidence back? Can we get back to frequent integration to highlight problems when they are most easily and cheaply resolved?
Integrating Continuously
I think so. Here’s a relatively simple solution to the problem.
The isolated and long-lived feature branches are their own separate lines of development. And so it’s best to start treating them as such. The development branch now really represents the most recent, usable, source for new features — it’s where they have to be forked from. Therefore, only features with regulatory approval can be merged back to development. The feature branches that are still being developed live on as they must (as develop/epic-name to separate them from the main development branch). But instead of working directly in those branches, which creates problems as multiple people attempt to work in the same branch, stepping on each other’s toes, I recommend that separate work branches (feature/epic-name/feature-name is a handy naming convention) are used for day-to-day work. These then are like the feature branches prescribed in the Git Flow model and serve to separate work being performed. These work branches are of course merged back to their respective main lines on a daily basis, and so work on any particular feature is integrated as rapidly as possible.
Feature branches off of Epic Mainlines:
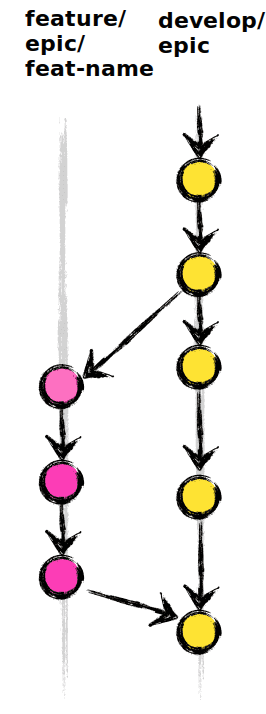
However, this alone doesn’t solve the larger integration problem. It just separates out the daily work being performed. This is I think where tooling can help.
It’s assumed that builds are being performed for all of these long-lived branches, that unit testing, coverage checking, static analysis, smoke testing, and other deeper tests are being performed on these builds (along with appropriate deployments to the environments in which these tests are being performed). These basic practices of continuous integration and continuous delivery are critical and cannot be skipped.
Merging back to develop (nightly, and for release)
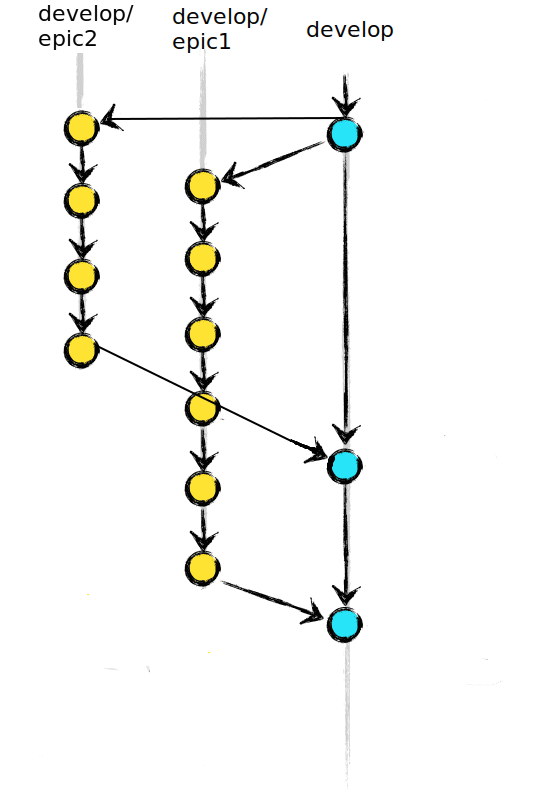
There is, however, additional work that can and should be performed. It takes relatively little work to get a list of all available feature branches, especially if a naming convention like “develop/epic-name” is enforced for these branches. Each of these branches can have a test merge performed with the main development branch on the continuous integration server. Merges should happen without the need for any intervention and conflicts should be reported to the team as integration failures. Successful merges should become builds, with the normal process of escalating rounds of testing and trial deployments occurring as appropriate. This is, for the record, the integration piece of continuous integration, and should be done on every push.
As a first pass, only one additional integration is needed. All of the develop/epic branches should be simultaneously merged together into the main development branch and another build performed. Any branches that fail to merge should again be reported out as integration failures, and the build and test process should be carried out on the branches that do manage to merge together successfully. We do, after all, want to gather as much data as possible on potential integration failures, and running tests on the parts that can be merged gets us more information on those branches in a live environment. And this process should be set up to occur nightly.
Why go through all this effort? First, doing the individual merges and builds with the development branch quickly highlights integration failures at the code level (when the merge is performed) and at the higher levels captured by automated tests. Then by merging everything together the overall health of the software can be assessed, just as if we weren’t forced to deal with these long-lived branches in the first place. Second, this forces the team to tackle integration problems early and often. This is one of the main mantras of CICD: fail early, fail often. Integration has to be done so do it as often as possible and it will become as painless as possible.
In particular, changes that make it into development can and should be reflected in the long-lived feature branches. These are changes that will be released and any future features will need to be developed with those approved features in mind. Merge failures indicate a feature that is being developed without this consideration and the whole team should be notified of that fact. The harder pill for any development team to swallow is going to be the latter requirement, that all features can be merged together. But consider this— in the best-case scenario, where all features being developed are approved, all features have to be merged together prior to release. So any issues highlighted by a failure to merge have to be dealt with eventually and so issues should absolutely be reported. Fail early, fail often!
Digging Deeper to Unearth Conflict
I mentioned before that this is only a first pass. There is a subtle issue with the approach outlined — it biases branches that come first in the ordering used to select branches (e.g. lexical). If two branches conflict, it’s the branch that’s chosen second that will be reported as failing. The actual problem might be subtle and only show up in the particular combination of several branches and it requires manual effort to figure out what has happened.
Again, tooling can help. Rather than blindly merging all branches together, a more deliberate approach can help narrow down the actual failure mode. Branches need to be merged together combinatorially, essentially testing each and every possible combination of branches. However, reports should not be sent out for every failure — that will, early on, be explosive in number, and cause the team to outright ignore these failures. Reports should only be sent out to tell the team about the largest set of branches that can be merged together and which sets of branches exclude each other. Builds and testing can then be done on these larger sets and a more nuanced picture of the overall software health can be established.
This is, of course, tricky to do right. Here’s one possible approach— get the list of all n feature branches and make sure they’re all checked out locally. Add the development branch to this list. Use a nested loop to go through this list twice and populate an n * n matrix with true where a merge succeeds and false where it fails. There are some shortcuts you can take to reduce the amount of work this takes. You don’t need to even consider the bottom half the matrix. If branch A merges with branch B then the merge in the other order will also succeed. Second, you don’t need to consider the central diagonal. Branch A will always “successfully” merge with A. That is, git will report “Already up-to-date” and give no further errors. Grab the branches that pass all their merges and do a build on those: they’re all good. Email the team with the branches that have failures, and report where these failures happen. You can go a little further than this and do separate builds for the sets of branches that do integrate together properly and report out on the health of these subsets. However, it’s ultimately easier at this point to just ask the team to fix the broken branches and make them integrate.
Do I Have To?
As you can imagine, this is a lot of work. Why do it if it isn’t necessary? It’s far easier to keep a single line of development and integrate all work into it frequently. The approach outlined here should only be used if it’s absolutely necessary. Hint: It’s probably not, unless the appropriate regulatory body requires it of you, the way the FDA did for us. This whole process, doing trial merges of branches trying to hunt down possible conflicts, it’s all unnecessary if the team is merging back to development regularly. All this work just gets us back (most of) the advantages of that rather simple strategy.
The product of all this work is deeply rewarding, however. The time it takes to integrate, test, and release code in a regulated environment will be substantially reduced. The team will have confidence, when it comes time to release, that the integrated codebase is the product they’ve been working to build. They’ll have confidence that the code works.
Thanks for reading and join me next time as I discuss the challenges posed by deployment in a tool-restricted environment.

